
こんにちは。てぃろです。
先日ハッカソンに出たときにはじめてAppSyncを使ったのですが、そのときにLambdaリゾルバーをPythonとServerless Frameworkを使って書きました。
せっかくなので今後も使いやすいサンプルとして残しておくためにシンプルに重要な部分のみを括りだして、解説記事と一緒にまとめておきます。
サンプルとして括りだしたソースはGitHubで公開しています。
デプロイの方法については、リポジトリのREADMEを参照してください。本記事ではソースの中身について解説していきます。是非ソースを見ながら読んでみてください。
ちなみに、記事はAppSyncやGraphQLの概要を知っている方を対象に書いています。
先にAppSyncとGraphQLの概要を知りたい方はこちらの解説記事も見てみてください。
AppSyncの全体像から設定すべきものを確認する
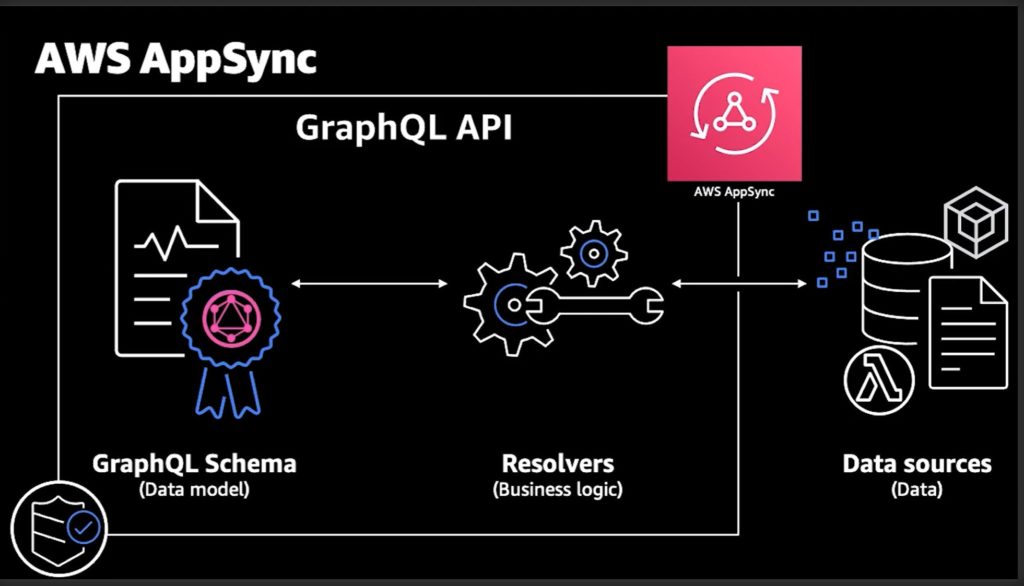
AppSyncは大きく3つの要素で構成されています。
- Schema:スキーマ、いわゆるデータモデル、ユーザからのリクエストとレスポンスの形を定義する
- Resolver:リゾルバー、ビジネスロジックでデータ処理を担当する
- DataSources:データソース、リゾルバーからアクセスするデータの保管場所
これらがうまく構築されてAppSyncは機能します。
しかし、実際にLambdaリゾルバーを設定していこうとすると、この3つをそのまま設定する、とはいきません。実際に設定を書くものを使って図を書き直してみると以下のようになります。
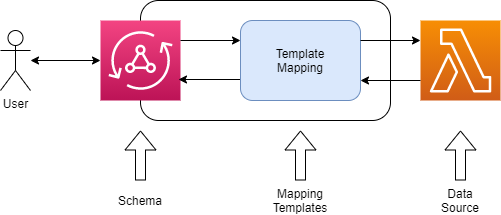
- Schema:前述のスキーマと同じ
- Mapping Template:スキーマとリゾルバーの間でどのような値の受け渡しを行うかを定義したテンプレート
- DataSource:Lambdaの場合、データソースでありながらリゾルバーとしてビジネスロジックの定義を行う
このようにMappingTemplateの設定が実は必要であり、Lambdaはデータソースでありつつリゾルバーでもある、ということです。
ちなみに、Mapping TemplateはLambdaリゾルバー特有のものではありません。Mapping Templateはただ値をマップするだけではなく、簡単なロジックを入れることも可能でやってみると奥が深い要素です。詳しくは公式ドキュメントをご覧ください。
結局、Lambdaリゾルバーを使うためには、
- Schemaの定義
- Mapping Templateの定義
- Resolverとして、Lambda関数をコーディング
- DataSourceとして、Lambdaを設定
という作業を進める必要があるというわけです。
次に、これらを再現性を持たせて進めるためにServerless Frameworkでの書き方を解説していきます。
プラグイン”serverless-appsync-plugin”を使ってAppSync定義をコード化
Serverless FrameworkでAppSyncを定義するためにはこちらのプラグインを使っていきます。
メインの設定は以下のようにcustomの部分に書きます。ソースの一部を抜粋します。
custom:
appSync:
name: ${opt:stage, self:provider.stage}-sls-sample
authenticationType: API_KEY
schema: ./sls_configurations/appsync/schema/sls_sample.graphql
dataSources:
${file(./sls_configurations/appsync/data-sources/sls_lambda.yml)}
mappingTemplatesLocation: ./sls_configurations/appsync/mapping-templates
mappingTemplates:
${file(./sls_configurations/appsync/mapping-templates-definitions/sls_sample_data.yml)}環境分けのための変数等が入っていてわかりにくいと思いますが、要するに以下の設定をしています。
- name:AppSyncの名前、マネジメントコンソールでも表示されます
- authenticationType:AppSyncへアクセスする際の認証方式を指定する
- schema:AppSyncのスキーマ定義ファイルを指定する
- dataSources:データソースの定義をリストで書く
- mappingTemplatesLocation:Mapping Templateのファイルを格納しているディレクトリパスを指定する
- mappingTemplates:どのスキーマとデータソースの間でどのMpping Templateを使うか定義する
全部解説すると長いので、動作させるために特に理解すべきポイントに絞って解説します。是非ソースを見ながら読んでみてください。
Lambdaの定義
Serverless Frameworkでは、Lambdaは以下のように定義します。ここはAppSync特有ではなく、Serverless Frameworkの通常の書き方です。
getSampleData:
handler: functions/appsync/get_sample_data.lambda_handler
description: 【sls sample】Get Sample Data
createSampleData:
handler: functions/appsync/create_sample_data.lambda_handler
description: 【sls sample】Create Sample DataAPI Gatewayなどとは違い、eventsは何も書かなくてOKです。
この中で重要なのはgetSampleDataとcreateSampleDataの二つです。これらはこのあとのdataSourcesの定義でLambdaの名前として使用します。
dataSourcesの定義
この設定でAppSyncでLambdaが使用可能なデータソースとして定義されます。
- type: AWS_LAMBDA
name: ${opt:stage, self:provider.stage}_getSampleData
config:
functionName: getSampleData
- type: AWS_LAMBDA
name: ${opt:stage, self:provider.stage}_createSampleData
config:
functionName: createSampleData設定の意味は以下の通りです。
- type:データソースのタイプを指定する、LambdaやDynamoDBなどが指定可能
- name:データソースの名前、任意の名前を付けることができる
- config.functionName:Lambdaリゾルバーの場合にLambda関数名を指定する
先ほど定義したLambdaの名前をconfig.functionNameに入れています。
この設定の中のnameは、このあとMapping Templateの設定で使用します。
schemaの定義
今回はgraphql形式で書いていきます。Lambdaリゾルバーだからといって変わるところがあるわけではありません。
ここで重要な設定はQueryとMutationの定義です。
つまり、以下の部分が特に重要です。
type Query {
getSampleData(id: ID!): SampleData
}
type Mutation {
createSampleData(input: SampleInput!): SampleData!
}これらはのちにMapping Templateの設定で使用します。
mappingTemplatesの定義
最後にMapping Templateの設定を書きます。
- dataSource: ${opt:stage, self:provider.stage}_getSampleData
type: Query
field: getSampleData
request: Query.lambda.request.vtl
response: Query.lambda.response.vtl
- dataSource: ${opt:stage, self:provider.stage}_createSampleData
type: Mutation
field: createSampleData
request: Query.lambda.request.vtl
response: Query.lambda.response.vtl- dataSources:先に定義したデータソースの名前
- type:アクセスさせるschemaのタイプ
- field:アクセスさせるschemaを具体的に指定
- request:受けたリクエストをLambdaに渡すためのテンプレート
- response:Lambdaから値を返す時のテンプレート
つまり、
- どのスキーマでリクエストを受けて(typeとfield)
- どんな形にマッピングし(request)
- どこのデータソースに渡して(dataSource)
- どんな形でマッピングしてレスポンスするか(response)
という形でこれまで定義したすべての要素をつないでいます。
ちなみに、ここで初めて登場したvtlファイルについてですが、これこそがリクエストとレスポンスの受け渡しの形式を決めています。今回はシンプルにただ受けとったデータをLambdaにそのまま流すことしかしていません。
そのため、Lambdaはスキーマに合わせたjsonを返すように書いています。以下のようにgetSampleDataはSampleDataの型です。
type SampleData {
id: ID!
name: String!
description: String!
}
type Query {
getSampleData(id: ID!): SampleData
}以下がLambdaの中身です。このように返り値をSampleData型の通りにしています。この構造はMutationになっても同じです。
def lambda_handler(event, context):
LOGGER.info(json.dumps(event, ensure_ascii=False))
id = event.get("id")
if id is None:
return
return {
"id": id,
"name": "Sample Name",
"description": "You are Done! Welcome to AppSync!"
}以上でAppSyncを最低限動作させるためのポイントは解説できました。あとは実際にAWSにデプロイするなど試してみてください。
まとめ
今回はAppSyncをServerless FrameworkとPythonを使って書いたのでそのポイントを解説していきました。
パッと見では設定する内容がかなり多くて嫌になりそうですが、中身を理解してみるとやってることは意外とシンプルだったということがわかると思います。
ただ、設定内容が多いことは否めません。
本番で使うことを考えると、スキーマもデータソースの数も爆発的に増えていくので管理が大変になります。
そうなったときには、私が今回サンプルでお見せしているようなファイル分割を試してください。少しは管理しやすくなると思います。
また、今回お見せしたものはLambdaリゾルバーを使える最低限の設定のみです。今後DynamoDBをデータソースに使う場合や、その他のAppSyncの機能についてはさらにいろいろ試しつつ解説記事にしていきたいと思います。
ハッカソンでの使い道をご覧になりたい方は、こちらの記事を参照してください。



